Bahdanau et al. (2014) - Attention Mechanisms
Bahdanau et al.'s 2014 paper introduced neural attention mechanisms, enabling models to focus on relevant parts of input sequences and transforming sequence-to-sequence learning.
The 2014 paper “Neural Machine Translation by Jointly Learning to Align and Translate” by Bahdanau, Cho, and Bengio introduced attention mechanisms to neural networks. Originally developed for machine translation, attention quickly became a foundational idea in deep learning, enabling models to selectively focus on relevant parts of an input sequence.
Attention mechanisms overcame key limitations in encoder-decoder architectures by allowing variable-length alignment between inputs and outputs. The idea of learning soft alignments inspired a new class of models - from Transformers to GPT - and now underpins virtually all state-of-the-art sequence models.
Historical Context
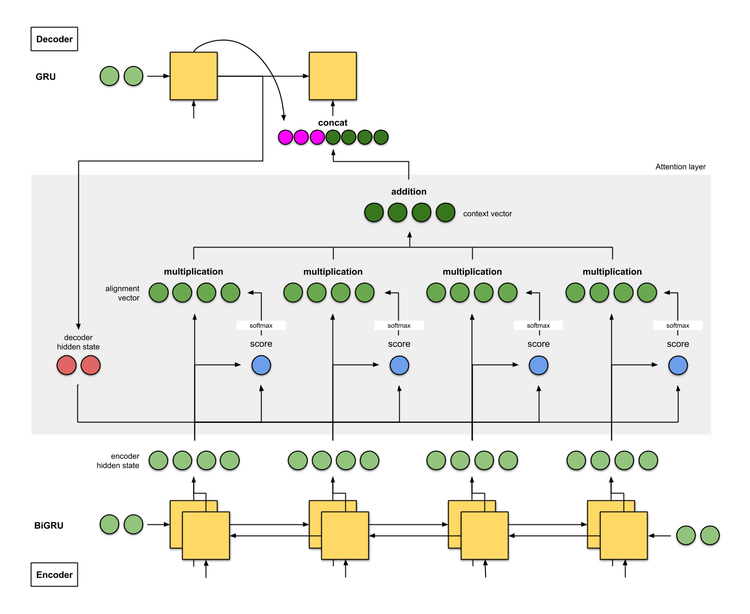
Early sequence-to-sequence models used a fixed-size vector to encode the entire input sequence. This bottleneck limited their ability to handle long or complex inputs.
Bahdanau et al. added an attention layer between the encoder and decoder. Rather than compressing the source into a single vector, the decoder dynamically computed a weighted sum over all encoder outputs at each step. This made it possible to learn context-dependent alignments between source and target tokens.
Technical Summary
In its original formulation, attention computes a context vector as a weighted average of encoder hidden states:
score = alignment\_function(decoder\_state, encoder\_state)
weights = softmax(score)
context = sum(weights \* encoder\_states)
Key components:
- Alignment function: Measures relevance between decoder state and each encoder state (e.g., dot product, MLP)
- Softmax weights: Normalize scores into a probability distribution
- Context vector: Guides the decoder’s next output step
Variants include:
- Additive attention (Bahdanau-style)
- Dot-product attention (Luong-style)
- Scaled dot-product attention (used in Transformers)
Evolution and Extensions
Attention evolved rapidly after 2014:
- Luong et al. (2015) streamlined and improved computational efficiency
- Self-attention was introduced in Transformers , enabling models to attend to different positions within the same sequence
- Multi-head attention allowed parallel attention subspaces
- Cross-attention connects encoder-decoder components in models like BERT , T5 , and diffusion models
Impact and Applications
Attention mechanisms are now standard in:
- Machine translation and summarization
- Large language models like GPT
- Vision Transformers (ViT)
- Audio and speech recognition
- Protein structure prediction (e.g., AlphaFold)
Their interpretability, via attention weights, also made them popular in early explainability research. Explainability, in this context, refers to efforts to understand and communicate how and why neural networks make specific decisions. In early attention-based models, researchers could inspect the learned attention weights to identify which parts of the input the model focused on, making the decision process more transparent. However, as models have grown more complex, especially in multi-layer and multi-head architectures, the clarity of these explanations has diminished.
Related Work
- Encoder-Decoder Architectures : Attention augments these systems
- Transformers : Scaled dot-product attention replaces recurrence
- GPT : Uses causal self-attention for generation
Further Reading
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate.
- Luong, M. T., Pham, H., & Manning, C. D. (2015). Effective Approaches to Attention-based Neural Machine Translation.
- Evolution of Model Architectures overview
- Tags:
- Papers
- Architectures