Rosenblatt (1958) - The Perceptron
Frank Rosenblatt's 1958 introduction of the Perceptron marked the birth of machine learning as a computational discipline, laying the foundation for modern neural networks.
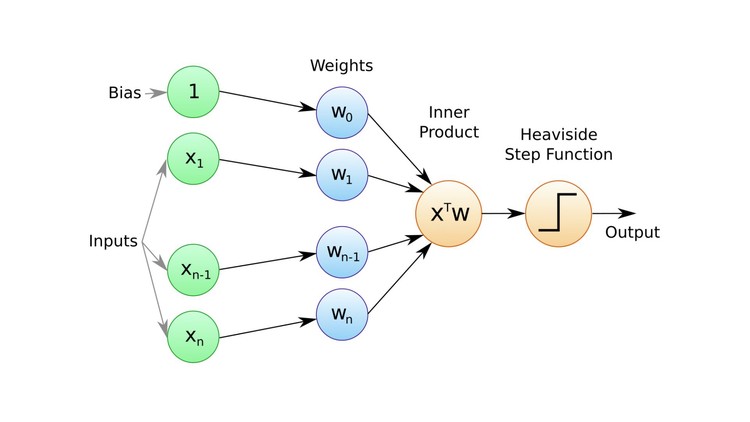
Frank Rosenblatt’s 1958 paper introduced the Perceptron, the first concrete implementation of a learning algorithm for artificial neural networks. Based on earlier theoretical work by McCulloch & Pitts , the Perceptron represented a shift from speculative ideas about machine intelligence - like those proposed by Turing - to tangible systems that could learn from data.
Historical Context
The concept of the Perceptron emerged in the post-war era of cybernetics and early computing. Building on McCulloch and Pitts’ binary neuron model and Hebb’s theory of synaptic learning, Rosenblatt sought to create machines that mimicked biological perception.
Working at Cornell Aeronautical Laboratory, Rosenblatt designed a two-layer model consisting of input units (sensory receptors) and an output unit (the “response cell”) connected by adjustable weights. His 1958 paper and demonstrations used a physical implementation known as the Mark I Perceptron, a hardware device that learned to classify visual patterns.
Technical Summary
The Perceptron is a type of linear classifier. It operates on binary inputs and learns a set of weights to decide whether to activate the output node based on a thresholded weighted sum:
if (w ⋅ x + b > 0):
output = 1
else:
output = 0
Where:
xis the input vectorwis the weight vectorbis the bias
Training occurs through an iterative rule: if the model misclassifies an input, it updates the weights to reduce future error. This rule embodies one of the earliest forms of supervised learning.
Key Properties
- Single-layer architecture: Only one decision boundary is learned.
- Online learning: The model updates weights after each example.
- Guaranteed convergence for linearly separable data (Perceptron Convergence Theorem).
Limitations and Criticism
The Perceptron sparked both enthusiasm and controversy. In 1969, Marvin Minsky and Seymour Papert’s book Perceptrons highlighted the model’s limitations - notably its inability to solve non-linearly separable problems like XOR. This critique significantly slowed neural network research for over a decade.
However, the core idea of learning weights from data would prove foundational. Multi-layer networks using the backpropagation algorithm , introduced in the 1980s by Rumelhart et al. , overcame the limitations of single-layer Perceptrons.
Influence on Later Architectures
Rosenblatt’s work initiated the lineage of models that now includes Convolutional Neural Networks , Deep Belief Nets , and Transformers . While modern architectures are vastly more complex, the fundamental concept of learning parameters from data traces directly to the Perceptron.
The idea that machines could improve their performance through exposure to examples laid the groundwork for today’s data-driven AI. Even now, perceptron-like units are the building blocks of deep neural networks.
Related Work
- McCulloch & Pitts : Theoretical precursor to the Perceptron
- Backpropagation : Overcoming Perceptron limitations
- Evolution of Model Architectures : Broader lineage
Further Reading
- Rosenblatt, F. (1958). The Perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386–408.
- Minsky, M., & Papert, S. (1969). Perceptrons. MIT Press.
- Historical overview in Turing (1950) and McCulloch & Pitts (1943)
- Tags:
- Papers
- Architectures