Vaswani et al. (2017) - Transformers
Transformers, introduced by Vaswani et al. in 2017, revolutionized sequence modeling with a fully attention-based architecture, replacing recurrence with parallelizable self-attention.
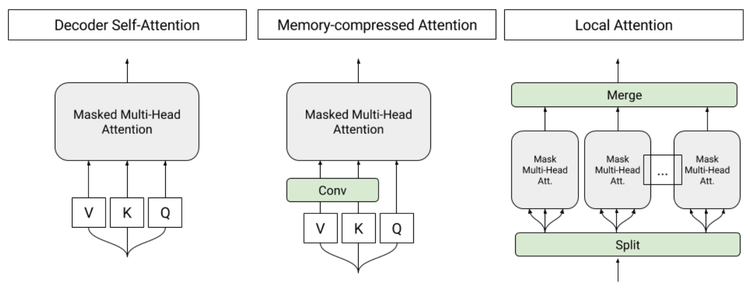
In 2017, the paper “Attention is All You Need” by Vaswani et al. introduced the Transformer architecture and fundamentally changed the trajectory of natural language processing (NLP) and deep learning. By eliminating recurrence entirely and relying on self-attention mechanisms, Transformers enabled highly parallelized, scalable architectures that quickly displaced LSTMs and other RNN-based models.
Transformers now serve as the foundation for most state-of-the-art models, including BERT , GPT , T5 , and many vision and multimodal systems.
Historical Context
Prior to Transformers, sequence modeling relied heavily on recurrent networks such as LSTMs , which suffered from limited parallelism and difficulty modeling long-range dependencies.
Attention mechanisms, introduced by Bahdanau et al. (2014) , had already shown promise in encoder-decoder architectures , particularly for neural machine translation.
The Transformer built on these ideas and removed recurrence entirely, allowing for vastly more efficient training on large datasets and enabling the era of pretraining and scale.
Technical Summary
The Transformer architecture consists of two main components:
- Encoder: Maps input sequences to continuous representations
- Decoder: Generates output sequences from these representations
Each block includes:
- Multi-head self-attention: Enables the model to attend to multiple parts of a sequence in parallel
- Position-wise feedforward layers: Adds nonlinear transformations
- Positional encoding: Injects order into otherwise permutation-invariant attention
- Residual connections and layer normalization: Stabilize training
Transformers are trained using backpropagation and can be stacked into deep networks. Unlike RNNs, they process all tokens simultaneously.
Key Contributions
- Replaced recurrence with fully parallelizable self-attention
- Enabled long-range dependency modeling without vanishing gradients
- Provided a general-purpose architecture for NLP, vision, and more
Impact and Applications
Transformers achieved state-of-the-art results in machine translation (e.g., WMT 2014) and quickly became the standard architecture for pretraining large models.
Modern applications include:
- Language models: GPT , BERT , T5
- Vision Transformers (ViT) and multimodal models (e.g., CLIP, Flamingo)
- Reinforcement learning and protein folding
Transformers are at the core of the generative AI boom, powering systems that can write, translate, summarize, and create across domains.
Related Work
- Attention Mechanisms : Core innovation underlying Transformers
- Encoder-Decoder Architectures : Transformer layout follows this paradigm
- GPT : Decoder-only adaptation for generative modeling
- BERT : Bidirectional encoder for language understanding
Further Reading
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is All You Need. NeurIPS.
- Alammar, J. (2018). The Illustrated Transformer.
- Evolution of Model Architectures overview
- Tags:
- Papers
- Architectures